Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
International Conference on Computational Linguistics (COLING), 2020
Oral presentation
PDF Code Slides Video Publisher
Abstract
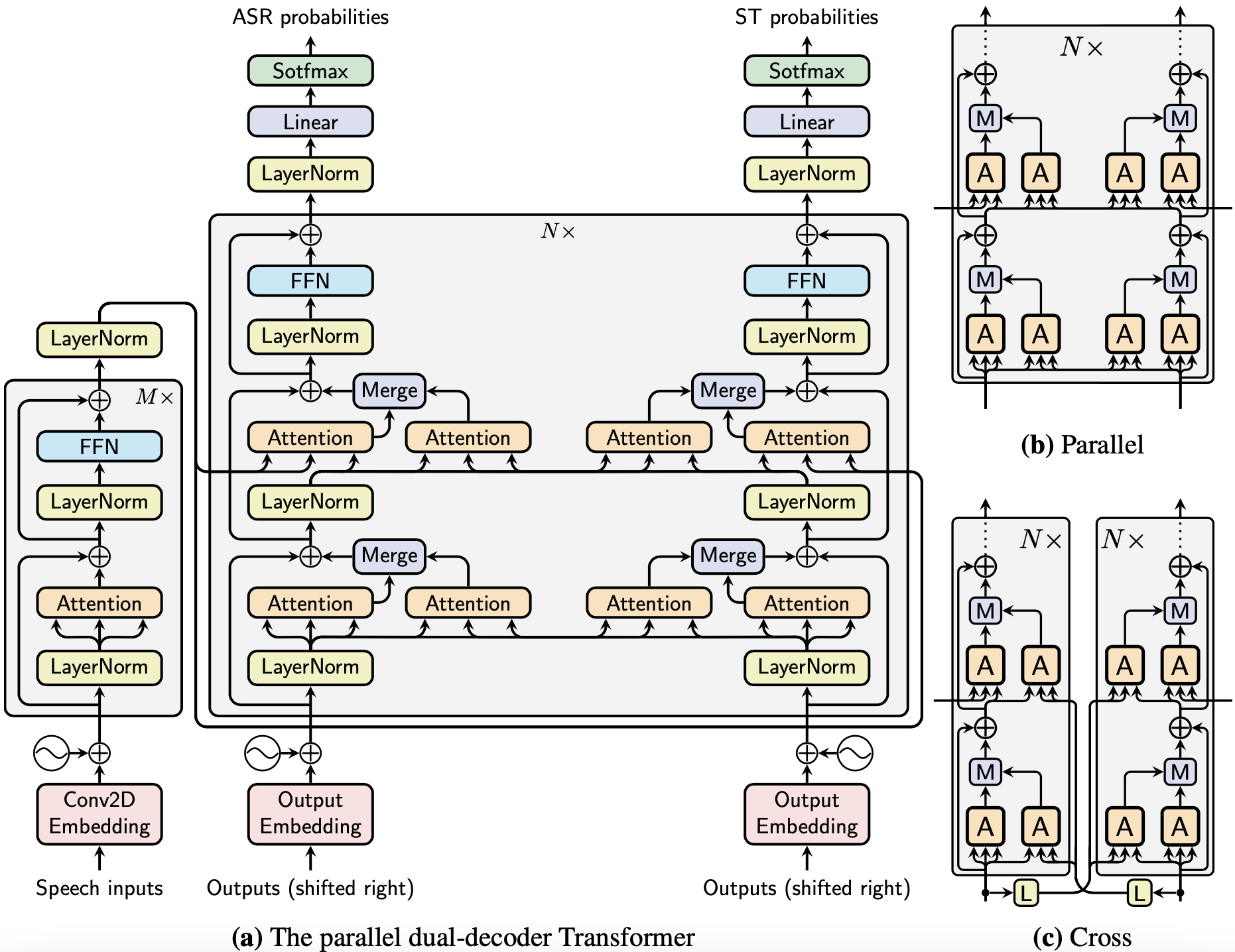
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture. Our code and pre-trained models are available at https://github.com/formiel/speech-translation.
Citation
@inproceedings{le2020dualdecoder,
author = {Hang Le and
Juan Miguel Pino and
Changhan Wang and
Jiatao Gu and
Didier Schwab and
Laurent Besacier},
title = {Dual-decoder Transformer for Joint Automatic Speech Recognition and
Multilingual Speech Translation},
booktitle = {Proceedings of the 28th International Conference on Computational Linguistics (COLING)},
pages = {3520--3533},
publisher = {International Committee on Computational Linguistics},
year = {2020}
}